Section outline
-
-
Seaborn can be used with different types of data, whether Python lists, NumPy arrays, or pandas DataFrames, although pandas DataFrames are generally preferred.

Wide-format :
Var1 Val1 Val2 Val3 Var2 Val1 Var3Val11 Var3Val12 Var3Val13 Val2 Var3Val21 Var3Val22 Var3Val23 Val3 Var3Val31 Var3Val32 Var3Val33 Long-format :
Var1 Var2 Var3 Observation1 Var1Val1 Var2Val1 Var3Val1 Observation2 Var1Val2 Var2Val2 Var3Val2 Observation3 Var1Val3 Var2Val3 Var3Val3 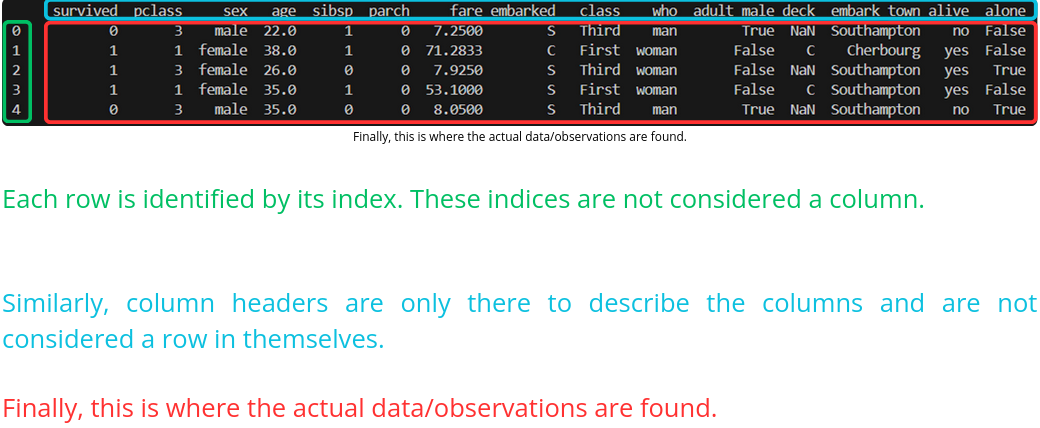
It can be useful to check whether any data is missing:
data=sns.load_dataset("penguins") print(data.isnull())#sur le tableau entier print(data.isnull().any())#sur chaque colonnedata.dropna(subset=["body_mass_g"])
-