Résumé de section
-
-

Ce cours est un tutoriel sur les différentes fonctionnalités de Seaborn. Un jupyter notebook sera fourni que vous pourrez tester sur GoogleCollab mais si vous voulez le faire tourner en local vous aurez besoin d'un environnement python et du nécessaire pour lire un jupyter notebook. L'intégralité du cours peut se faire sur la page Moodle mais un diaporama contenant les informations du cours est aussi disponible dans la partie Ressources. La formation peut être suivie au rythme voulue mais un ordre de grandeur pour une lecture de la formation est d'environ 2h.
-
-
-
Seaborn est une bibliothèque Python utilisée pour faire des visualisations de données (graphiques) de manière simple et esthétique.
Seaborn peut s'utiliser avec différents types de données, que ce soit des listes python, des tableaux numpy ou des dataframes pandas, bien que le dataframe de pandas soit à privilégier.

Il y a différents formats de tableaux de données :
Wide-format :
Var1 Valeur1 Valeur2 Valeur3 Var2 Valeur1 Var3Val11 Var3Val12 Var3Val13 Valeur2 Var3Val21 Var3Val22 Var3Val23 Valeur3 Var3Val31 Var3Val32 Var3Val33 Le wide format est souvent plus naturel pour les humains, et certains algorithmes ou fonctions attendent ce format. Voici un exemple :
Jour Temp_Paris Temp_Lyon Lundi 20 23 Mardi 19 24 Long-format :
Var1 Var2 Var3 Observation1 Var1Val1 Var2Val1 Var3Val1 Observation2 Var1Val2 Var2Val2 Var3Val2 Observation3 Var1Val3 Var2Val3 Var3Val3 Le format classique est le long-format qui permet d'avoir des points de données avec beaucoup de variables différentes. Voici l'exemple précédent en long-format :
Jour Ville Température Lundi Paris 20 Lundi Lyon 23 Mardi Paris 19 Mardi Lyon 24 Voici une description d'un tableau dans ce format :
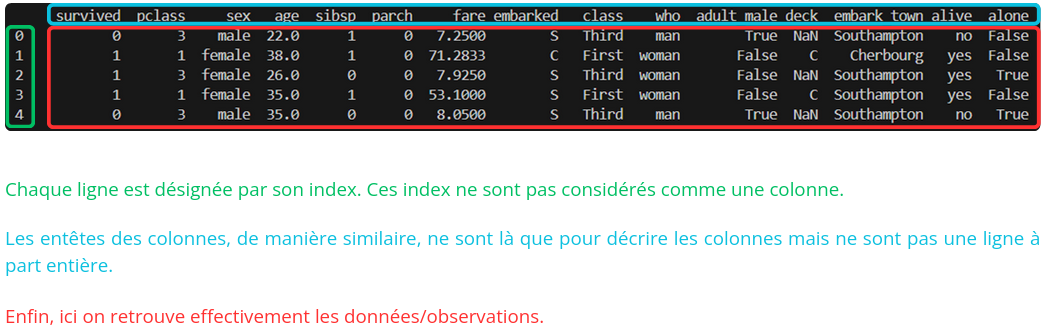
Il peut être intéressant de vérifier si des données sont manquantes, notamment si des algorithmes ne peuvent pas le supporter ou si ca risque de biaiser les résultats, ou le simple fait qu'avoir des données complètes facilite l'aggrégation de données par exemple. Voici le code permettant de le vérifier :
data=sns.load_dataset("penguins") print(data.isnull())#sur le tableau entier print(data.isnull().any())#sur chaque colonnePuis si l’on ne veut pas considérer les observations avec valeurs nulles pour une variable par exemple :
data.dropna(subset=["body_mass_g"])Il faut cependant faire attention si l'on a un dataset plutôt petit, et si par exemple les données manquantes appartiennent toujours à la même variable cela peut introduire un biai. C'est au final à l'appréciation de l'utilisateur.
Ce cours comprend des cellules de code modifiables et exécutables. La structure sera toujours la même dans chaque sous-section : Tout d'abord une cellule servant à importer les librairies nécessaires et récupérer les datasets que nous utiliserons, puis dans le reste de la sous-section des cellules de codes modifiables pour illustrer les différentes fonctions.
-
-
-
-
-
La fonction relplot() permet de faire des graphiques de type nuage de points et de type courbe.
Voici la signature de la fonction :

Il y évidemment une documentation accessible sur internet, donc on ne va passer que sur les éléments les plus essentiels pour pouvoir afficher ce dont on a besoin le plus vite possible, à savoir :
Nom du paramètre Explications Ce qui lui faut comme format Exemple data Il faut donner au paramètre data le tableau entier que vous traitez
DataFrame, Series, dict, array, or list of arrays data=tableau x variable du tableau utilisée pour les abscisses Chaine de caractères correspondant à une variable du tableau x="poids" y variable du tableau utilisée pour les ordonnées Chaine de caractères correspondant à une variable du tableau y=”taille” hue variable du tableau permettant de rajouter une dimension avec de la couleur Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière hue=”age” size variable du tableau qui controlera la taille des points Chaine de caractères correspondant à une variable du tableau, numérique size=”argent” style variable du tableau qui controlera le style des points Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière style=”sex” row variable du tableau qui permettra de créer un tableau de graphiques, ici les lignes Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière row=”catégorie” col variable du tableau qui permettra de créer un tableau de graphiques, ici les colonnes Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière col=”métier” kind type de graphique que l’on veut Chaine de caractères, 2 choix possibles kind=”scatter” ou kind=”line”
Voici un exemple avec le code suivant, que vous pouvez exécuter :
On peut constater que col permet de faire différents graphiques sur une même figure, hue permet à l'aide de couleurs de distinguer une variable et style permet à l'aide de la forme des points de distinguer une autre variable. Vous pouvez tester différents paramètres et relancer le code.
On peut rajouter des ellipses sur des relplot scatter, pour dessiner dessus il faut récupérer l’ax :Ellipse vient de matplotlib.patches.
On peut aussi afficher des lignes en modifiant le kind en "line" :
size n'est pas utilisable avec le graphique de kind "line".
Cette fois style modifie le style de ligne selon la valeur de la variable "sex".
-
-
-
-
-
Le displot() permet d'afficher différents types de distributions.

Nom du paramètre Explications Ce qui lui faut comme format Exemple data Il faut donner au paramètre data le tableau entier que vous traitez
DataFrame, Series, dict, array, or list of arrays data=tableau x variable du tableau utilisée pour les abscisses Chaine de caractères correspondant à une variable du tableau x="poids" y variable du tableau utilisée pour les ordonnées Chaine de caractères correspondant à une variable du tableau y=”taille” hue variable du tableau permettant de rajouter une dimension avec de la couleur Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière hue=”age” row variable du tableau qui permettra de créer un tableau de graphiques, ici les lignes Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière row=”catégorie” col variable du tableau qui permettra de créer un tableau de graphiques, ici les colonnes Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière col=”métier” kind type de graphe que l’on veut Chaine de caractères, 3 choix possibles kind=”hist”,kind=”kde” ou kind=”ecdf” rug permet de voir les observations individuelles sur les axes. Booléen rug=True Voila un code modifiable d'exemple qui permet de faire un histogramme:Si l’on ne renseigne pas la donnée à mettre en ordonnée y, l’ordonnée sera le nombre d’occurence, et si l’on ne renseigne pas le kind c’est un histogramme par défaut. L’argument bins controle le nombre de barres. Le paramètre rug permet de voir les observations individuelles sur les axes du graphique.
Nous avons aussi accès à la kernel density estimation(KDE) pour estimer une distribution. Voici un code d'exemple d'utilisation :
Si l'on renseigne une variable pour y :
Un graphique de ce type se lit comme une carte de niveau. Chaque ligne correspond à des points ayant des densités de probabilités proches. Les centres de lignes sont les zones de plus haute densité.
Le dernier type de distribution disponible est l'ECDF(empirical distribution function). On ne peut pas renseigner y pour cette distribution étant donné qu'elle est monovariationnelle.
Le paramètre row permet d'afficher encore plus de graphique selon une autre variable des données, les données comportent 3 espèces de pingouins on a donc 3 lignes de graphique, il y a 2 sexes dans les données on a donc 2 colonnes. height permet de contrôler la hauteur des graphiques.
-
-
-
-
-
Une représentation graphique de données classique est la boîte à moustache qui est accessible via boxplot().

Nom du paramètre Explications Ce qui lui faut comme format Exemple data Il faut donner au paramètre data le tableau entier que vous traitez
DataFrame, Series, dict, array, or list of arrays data=tableau x variable du tableau utilisée pour les abscisses Chaine de caractères correspondant à une variable du tableau x="poids" y variable du tableau utilisée pour les ordonnées Chaine de caractères correspondant à une variable du tableau y=”taille” hue variable du tableau permettant de rajouter une dimension avec de la couleur Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière hue=”age” dodge variable permettant de choisir si les graphiques peuvent se superposer Booléen dodge=False width Variable permettant de contrôler les largeurs des boîtes. Valeur flottante width=0.5 gap Variable permettant de contrôler l’écart entre les différentes boîtes “dodgées” Valeur flottante gap=0.1
Voici un exemple de code que vous pouvez modifier et exécuter :
De base gap vaut 0. L’orientation est gérée automatiquement par seaborn, mais si le graphique est bidimensionnel avec 2 variables numériques on peut la chosir avec orient qui vaut "h" ou "v".log_scale permet de changer l’échelle. Une valeur numérique définit la base, qui de base est la base 10. Si le graphique est bidimensionnel 2 valeurs peuvent être données, une pour chaque axe.
Le diagramme en violon est aussi accessible via violinplot().

Nom du paramètre Explications Ce qui lui faut comme format Exemple data Il faut donner au paramètre data le tableau entier que vous traitez
DataFrame, Series, dict, array, or list of arrays data=tableau x variable du tableau utilisée pour les abscisses Chaine de caractères correspondant à une variable du tableau x="poids" y variable du tableau utilisée pour les ordonnées Chaine de caractères correspondant à une variable du tableau y=”taille” hue variable du tableau permettant de rajouter une dimension avec de la couleur Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière hue=”age” inner variable permettant de contrôler la représentation des données dans le violon Chaine de caractères correspondant à un type de représentation inner=”box”,inner=”quart”,inner=”point” split Variable permettant de choisir si la représentation est symétrique. Booléen split=True width Variable permettant de contrôler la largeur des violons. Valeur flottante width=0.5 dodge variable permettant de choisir si les graphes peuvent se superposer Booléen dodge=False gap Variable permettant de contrôler l’écart entre les différentes boîtes “dodgées” Valeur flottante gap=0.1 Voici un exemple de code à exécuter :
split permet d'afficher 2 distributions sur un même violinplot, étant donnés que ceux-ci sont symétriques. linewidth contrôle l'épaisseur des lignes de contour.
Nous avons affiché les points individuels dans le violin plot mais nous pouvons choisir d'afficher une boîte à moustache miniature avec inner="box" :
-
-
-
-
-
Si l'on souhaite faire des régressions linéaires, seaborn a une fonction prédisposée : regplot().

Nom du paramètre Explications Ce qui lui faut comme format Exemple data Il faut donner au paramètre data le tableau entier que vous traitez
DataFrame, Series, dict, array, or list of arrays data=tableau x variable du tableau utilisée pour les abscisses Chaine de caractères correspondant à une variable du tableau x="poids" y variable du tableau utilisée pour les ordonnées Chaine de caractères correspondant à une variable du tableau y=”taille” ci variable permettant de contrôler l’intervalle de confiance affiché Entier entre 0 et 100. ci=99 nboot variable permettant d’indiquer le nombre de réechantillonage bootstrap réalisés. Entier nboot=100 seed variable indiquant une graine pour le bootstrap. Permet la reproductibilité. Entier seed=42 logistic Variable permettant de choisir de faire une régression logistique Booléen logistic=True lowess Variable permettant de choisir de faire une régression LOWESS. Booléen lowess=True robust Variable permettant de choisir de faire une régression robuste. Booléen robust=True regplot() permet aussi d'afficher l'intervalle de confiance de la courbe, par défaut à 95%.
Voici un exemple de code modifiable :
Ici nous sommes confiant à 70% que la vraie courbe se trouve dans l'intervalle affiché sur le graphique. nboot de base vaut 1000, augmenter cette valeur entrainera forcément un temps d'exécution plus long du code car il devra faire des rééchantillonages supplémentaires. seed permet de pour en voir toujours reproduire les mêmes échantillonages utilisant un entier "graine", pratique pour la reproductibilité lors de l'écriture d'un article scientifique ou pour vérifier le fonctionnement d'une méthode.
On peut modifier le type en choisissant une méthode de régression, par exemple le paramètre lowess et en le mettant à True :
L’intervalle de confiance n’est pas affiché lorsque l’on utilise une lowess.
Une autre option est le lmplot() qui est plus adapté pour faire des régression mais sur plusieurs graphiques :

Nom du paramètre Explications Ce qui lui faut comme format Exemple data Il faut donner au paramètre data le tableau entier que vous traitez
DataFrame, Series, dict, array, or list of arrays data=tableau x variable du tableau utilisée pour les abscisses Chaine de caractères correspondant à une variable du tableau x="poids" y variable du tableau utilisée pour les ordonnées Chaine de caractères correspondant à une variable du tableau y=”taille” hue variable du tableau permettant de rajouter une dimension avec de la couleur Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière hue=”age” row variable du tableau qui permettra de créer un tableau de graphiques, ici les lignes Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière row=”catégorie” col variable du tableau qui permettra de créer un tableau de graphiques, ici les colonnes Chaine de caractères correspondant à une variable du tableau, catégorielle ou entière col=”métier” ci variable permettant de contrôler l’intervalle de confiance affiché Entier entre 0 et 100. ci=99 nboot variable permettant d’indiquer le nombre de réechantillonage bootstrap réalisés. Entier nboot=100 lowess Variable permettant de choisir de faire une régression LOWESS. Booléen lowess=True Voici un exemple de code :
Les régressions robust et logistic sont aussi disponibles comme pour regplot(). nboot et seed aussi.
-
-
-
-
-
Seaborn permet aussi de faire des heatmap avec heatmap().

Nom du paramètre Explications Ce qui lui faut comme format Exemple data Il faut donner au paramètre data le tableau entier que vous traitez
DataFrame, Series, dict, array, or list of arrays data=tableau cmap Couleurs de la heatmap. Soit une palette de matplotlib soit une personalisée. Chaîne de caractères correspondant à une palette ou une color_palette de seaborn. cmap=”viridis” ou cmap = sns.color_palette("light:blue", as_cmap=True) annot Variable qui choisit si on affiche les valeurs des cellules Booléen annot=True, vaut False par défaut vmin Valeur minimum qui sera prise en compte pour la colormap Valeur flottante vmin=30.6 vmax Valeur maximale qui sera prise en compte pour la colormap Valeur flottante vmax=42 linecolor Variable permettant de choisir la couleur des lignes entre les cellules. Chaîne de caractère correspondant à une couleur linecolor=”blue” linewidths Variable contrôlant l’épaisseur des lignes entre les cellules Valeur flottante linewidths=0.2 ou linewidths=10 mask Variable permettant de contrôler les valeurs prises en compte dans la heatmap. Tableau de booléen au même format que data. mask=tableau_mask
Voici un exemple de code :
Cellule 2← ExécutionOn utilise pivot afin de formater les données dans l'ordre que l'on veut :
-
index donne la variable des ordonnées
-
columns donne la variable des abscisses
-
values doit être une variable numérique et c'est ce que la heatmap va colorer.
Cellule 3← ExécutionAvec les paramètres vmin et vmax on peut choisir la plage de valeur sur laquelle la heatmap s'appliquera, et on a aussi des options graphiques comme avec linecolor et linewidths pour les lignes entre les cases. annot affiche les valeurs sur chaque case de la heatmap.
Si l'on a besoin d'avoir du clustering sur la heatmap on peut utiliser la clustermap() de Seaborn. Chose à savoir cette fonction nécessite scipy, il faudra donc l'installer sur l'environnement sur lequel vous travaillez. Si vous êtes sur le Collab, ca ne sera pas nécessaire vous pourrez l'importer directement.

Nom du paramètre Explications Ce qui lui faut comme format Exemple data Il faut donner au paramètre data le tableau entier que vous traitez
DataFrame, Series, dict, array, or list of arrays data=tableau method Méthode scipy pour faire le clustering Chaîne de caractère correspondant à une méthode de scipy method=’centroid’ metric Métrique scipy utilisée pour faire le clustering Chaîne de caractère correspondant à une métrique de scipy metric=’jaccard’ z_score Variable permettant de centrer et réduire les données. 0 pour centrer et réduire les lignes, 1 pour les colonnes z_score=0 standard_scale Variable permettant de normaliser les données. 0 pour normaliser les lignes, 1 pour les colonnes standard_scale=1 row_cluster,
col_cluster
Variables permettant de choisir les axes de clustering Booléen row_cluster=False, faut True par défaut figsize Variable contrôlant la taille de la figure tuple(largeur,hauteur) figsize=(4,4) dendrogram_ratio Variable contrôlant le ratio de taille des dendogram tuple(ratio de ligne, ratio de colonne) dendrogram_ratio=(0.2,0.1) cbar_pos Variable contrôlant la position de la barre de couleur. tuple(gauche,bas,largeur,hauteur) cbar_pos=(0,0.1,0.05,0.6)
Voici un exemple de code :
On retire la variable en trop avec pop() pour pouvoir faire le clustering qui est "species", on la réutilisera juste après.
Les dendrogrammes sont les arbres sur le côté de la clustermap qui représentent les différents regroupement effectués.
Maintenant explorons différents paramètres :
row_cluster permet de regrouper les lignes selon leur similarité pour faire apparaitre des groupes. dendrogram_ratio permet de contrôler la taille des dendrogrammes, la première valeur est pour celui à gauche et la seconde celui en haut. row_colors permet de rajouter une couleur à côté des lignes. Ici avec les lignes précédentes on a l'espèce de chaque ligne de renseignée. metric permet de choisir la distance de similarité utilisée et method l'algorithme utilisé pour faire les regroupements. z_score à 1 indique qu'on normalise sur les lignes. cbar_pos permet de choisir la position de la cbar. annot permet d'afficher les valeurs de chaque case. figsize permet de contrôler la taille de la figure.
-
-
-
-
-
-
-
La fonction catplot() permet de faire différents types de graphe :

Nom du paramètre Explications Ce qui lui faut comme format Exemple data Il faut donner au paramètre data le tableau entier que vous traitez
DataFrame, Series, dict, array, or list of arrays data=tableau cmap Couleurs de la heatmap. Soit une palette de matplotlib soit une personalisée. Chaîne de caractères correspondant à une palette ou une color_palette de seaborn. cmap=”viridis” ou cmap = sns.color_palette("light:blue", as_cmap=True) annot Variable qui choisit si on affiche les valeurs des cellules Booléen annot=True, vaut False par défaut vmin Valeur minimum qui sera prise en compte pour la colormap Valeur flottante vmin=30.6 vmax Valeur maximale qui sera prise en compte pour la colormap Valeur flottante vmax=42 linecolor Variable permettant de choisir la couleur des lignes entre les cellules. Chaîne de caractère correspondant à une couleur linecolor=”blue” linewidths Variable contrôlant l’épaisseur des lignes entre les cellules Valeur flottante linewidths=0.2 ou linewidths=10 mask Variable permettant de contrôler les valeurs prises en compte dans la heatmap. Tableau de booléen au même format que data. mask=tableau_mask Il y a différents kind que nous pouvons utiliser :
- strip
- swarm
- violin
- box
- boxen
- point
- bar
- count
Les graphiques "point" et "bar" affichent la moyenne ainsi que l'intervalle de confiance sur cette moyenne car elles sont calculées avec du rééchantillonnage bootstrap.
Nous pouvons utiliser les paramètres des méthodes choisies. Par exemple les boxplot() ont le paramètre fill donc on peut le spécifier dans la fonction catplot().
-
-
-
-
-
-
Depuis la mise à jour 0.12 de Seaborn des objets seaborn ont été introduits. Ceux-ci constituent une alternative puissante aux fonctions de plot originelles. Les objects sont inspirés de ggplot2 de R.
Nous allons prendre un exemple simple. Tout d'abord on importe les objets de la manière suivante :
import seaborn.objects as soLa manière de construire des graphiques avec les objets est spécifique. Une seule fonction permet de faire des graphiques :
so.Plot()A celle-ci nous indiquons les données que nous allons utiliser :
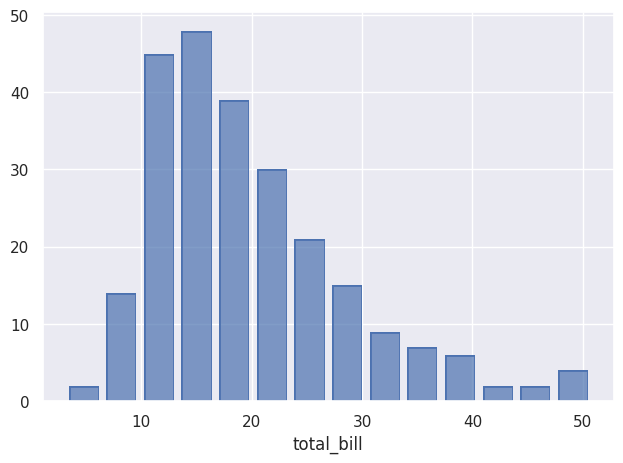
so.Plot(tips,x=”total_bill”)Ici tips est le dataset tips de Seaborn.
Une fois que l'on a spécifié les données il reste à décider ce que nous allons en faire avec add(), ici un histogramme :
so.Plot(tips,x=”total_bill”).add(so.Bar(),so.Hist()).show()Et voici le résultat :
-
-
-
-
-
Il y a différentes options visuelles disponibles sur Seaborn, que ce soit au niveau du style de point, de courbe ou des couleurs.
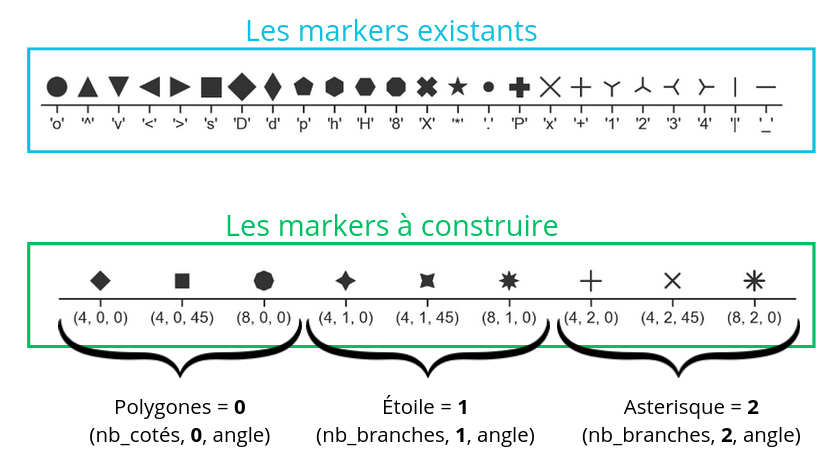
Voila un exemple de code :
Nous pouvons aussi modifier le type de lignes que nous utilisons :

Voici un exemple :
Nous pouvons aussi choisir des couleurs spécifiques :

Voici un exemple :
On peut aussi définir les couleurs à l'aide de palettes de couleur :
Et voici un exemple reprenant un code précédent :
-