Résumé de section
-
-
Seaborn est une bibliothèque Python utilisée pour faire des visualisations de données (graphiques) de manière simple et esthétique.
Seaborn peut s'utiliser avec différents types de données, que ce soit des listes python, des tableaux numpy ou des dataframes pandas, bien que le dataframe de pandas soit à privilégier.

Il y a différents formats de tableaux de données :
Wide-format :
Var1 Valeur1 Valeur2 Valeur3 Var2 Valeur1 Var3Val11 Var3Val12 Var3Val13 Valeur2 Var3Val21 Var3Val22 Var3Val23 Valeur3 Var3Val31 Var3Val32 Var3Val33 Le wide format est souvent plus naturel pour les humains, et certains algorithmes ou fonctions attendent ce format. Voici un exemple :
Jour Temp_Paris Temp_Lyon Lundi 20 23 Mardi 19 24 Long-format :
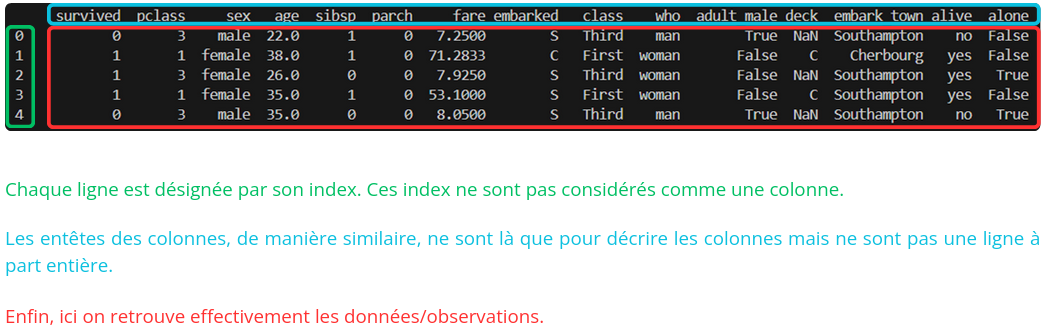
Var1 Var2 Var3 Observation1 Var1Val1 Var2Val1 Var3Val1 Observation2 Var1Val2 Var2Val2 Var3Val2 Observation3 Var1Val3 Var2Val3 Var3Val3 Le format classique est le long-format qui permet d'avoir des points de données avec beaucoup de variables différentes. Voici l'exemple précédent en long-format :
Jour Ville Température Lundi Paris 20 Lundi Lyon 23 Mardi Paris 19 Mardi Lyon 24 Voici une description d'un tableau dans ce format :
Il peut être intéressant de vérifier si des données sont manquantes, notamment si des algorithmes ne peuvent pas le supporter ou si ca risque de biaiser les résultats, ou le simple fait qu'avoir des données complètes facilite l'aggrégation de données par exemple. Voici le code permettant de le vérifier :
data=sns.load_dataset("penguins") print(data.isnull())#sur le tableau entier print(data.isnull().any())#sur chaque colonnePuis si l’on ne veut pas considérer les observations avec valeurs nulles pour une variable par exemple :
data.dropna(subset=["body_mass_g"])Il faut cependant faire attention si l'on a un dataset plutôt petit, et si par exemple les données manquantes appartiennent toujours à la même variable cela peut introduire un biai. C'est au final à l'appréciation de l'utilisateur.
Ce cours comprend des cellules de code modifiables et exécutables. La structure sera toujours la même dans chaque sous-section : Tout d'abord une cellule servant à importer les librairies nécessaires et récupérer les datasets que nous utiliserons, puis dans le reste de la sous-section des cellules de codes modifiables pour illustrer les différentes fonctions.
-