HAH811E9 - Science des Données - Niveau 1
Perfilado de sección
-
Contexte et objectif général :
A la croisée de plusieurs champs disciplinaires : mathématiques, probabilités, statistiques, informatique, théorie de l’information et visualisation, la science des données met en œuvre différents outils d’analyse de données afin d’extraire automatiquement des informations utiles, des connaissances, à partir de données potentiellement massives. Le but ultime est de rendre cette information plus facile à exploiter, la protéger et la valoriser. Elle pourra servir de base ensuite à des processus d’évaluation et d’aide à la décision.
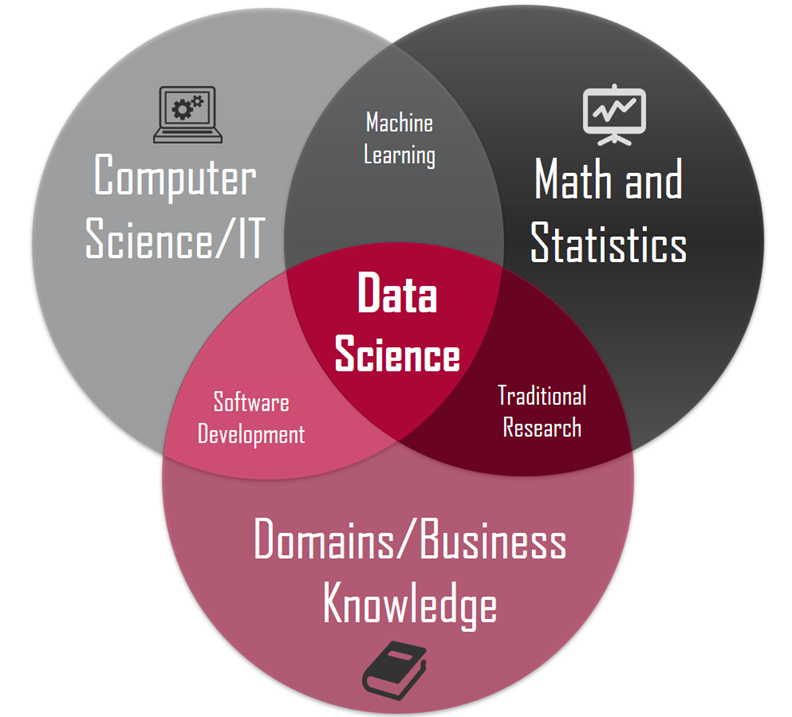
Source : https://towardsdatascience.com/introduction-to-statistics-e9d72d818745
Ce cours est organisé en 2 UEs. La première de Master 1 permettra aux étudiant d'acquérir les bases mathématiques et informatiques de la science des données. La seconde de Master 2 abordera les notions plus avancées d'intelligence artificielle et d'apprentissage artificiel.
UE Science des Données - Niveau 1 (Master 1)
Les techniques actuellement mises en avant en intelligence artificielle reposent sur l'utilisation de données, nombreuses et hétérogènes, qui peuvent être croisées, analysées, afin de faire émerger des comportements récurrents, d'expliquer certains phénomènes, voire de prédire certains faits. Cette introduction permet de décrire les contextes propices à ce genre d'approches et donner un inventaire des techniques utilisées dans le domaine. Cet enseignement a pour objectif de renforcer les compétences théoriques avec un approfondissement des statistiques et de la théorie des probabilités. D'autre part, les étudiants seront formés à l'utilisation de langages informatiques (SQL et R) pour réaliser des projets permettant de mettre en pratique les aspects théoriques de la science des données.
Mots clés : probabilités, statistiques, base de données, apprentissage artificiel, R, sql.
Prérequis : notions de base en probabilités, statistiques et programmation.
Intervenants :
- Gérard Dray (gerard.dray at mines-ales.fr) - Enseignant Chercheur - EuroMov Digital Health in Motion, Univ Montpellier, IMT Mines Ales, Ales, France
- Nicolas Sutton-Charani (nicolas.sutton-charani at mines-ales.fr)- Enseignant Chercheur - EuroMov Digital Health in Motion, Univ Montpellier, IMT Mines Ales, Ales, France
- Pierre Jean - Ingénieur de Recherche (pierre.jean at mines-ales.fr) - EuroMov Digital Health in Motion, Univ Montpellier, IMT Mines Ales, Ales, France
-
-
Bonjour,
Demain, jeudi 11 février 2026, nous terminerons l’initiation au « NoCode Machine Learning » avec le logiciel Orange Data Mining.
La seconde partie de la séance sera consacrée à la présentation du TP évalué, ainsi qu’à son lancement.
Merci de venir avec votre ordinateur et Orange Data Mining installé.
-
-
Travaux Pratiques
Prédiction des maladies du foie
Problématique
Les maladies du foie représentent un enjeu majeur de santé publique, notamment en Inde. La détection précoce de ces pathologies est essentielle pour améliorer les résultats cliniques. Le jeu de données Indian Liver Patient Dataset (ILPD) a été collecté dans cette optique, afin de fournir un support aux médecins pour identifier plus rapidement les patients atteints. Il contient des informations cliniques et biologiques (bilirubine, enzymes hépatiques, albumine…) permettant de modéliser le risque.
Objectif du TP
Développer un modèle de machine learning capable de prédire la présence d'une maladie du foie à partir de données cliniques, en utilisant l'outil Orange.
Compétences visées
- Prétraitement et analyse de données biomédicales.
- Construction et évaluation de modèles de classification.
- Interprétation des résultats dans une démarche d’aide à la décision médicale.Sujet du TP
1. Présentation du jeu de données
583 patients, dont 416 atteints et 167 non atteints. Variables : âge, sexe, bilirubine, enzymes hépatiques, protéines, albumine, etc.
2. Préparation des données
Chargement et exploration du fichier dans Orange. Traitement des valeurs manquantes et des variables qualitatives. Normalisation des variables si nécessaire.
3. Analyse exploratoire
Statistiques descriptives. Visualisations des distributions et des corrélations. Observation des différences entre les groupes (malades / non malades).
4. Modélisation
Application d’au moins trois algorithmes : régression logistique, k-NN, forêts aléatoires, SVM… Validation croisée pour évaluer les performances.
5. Évaluation
Utiliser uniquement la F1-mesure pour comparer les modèles. Justifier le choix du modèle final.
6. Interprétation
Analyse des variables importantes. Discussion sur l’usage potentiel du modèle dans un contexte clinique.
Modalités de rendu
Le rendu est à déposer sur l’ENT de l’Université de Montpellier. Il devra comprendre :
- Un compte rendu (PDF) présentant les étapes réalisées, les résultats obtenus et leur interprétation.
- Les fichiers Orange (.ows) correspondant aux workflows utilisés.
- Possibilité de travailler en monôme ou en binôme
- Nommage des fichiers :
- Nom1_Nom2.pdf
- Nom1_Nom2.ows
Recommandations pour organiser votre travail
- Commencer par une exploration visuelle des données pour repérer les anomalies.
- Documenter chaque étape dans le compte rendu (préparation, choix de modèles, résultats, interprétation).
- Tester plusieurs modèles et paramètres pour choisir celui ayant la meilleure F1-mesure.
- Sauvegarder régulièrement vos workflows (.ows) dans Orange.
- Soigner la qualité de la rédaction du rapport, y compris les légendes des figures.
Ressources
-
Jeu de données "Indian Liver Patient Dataset" (ILPD) : Lien vers le dataset
-
Documentation d'Orange : Lien vers la documentation
-
Tutoriel sur l'utilisation d'Orange pour le machine learning : Lien vers le tutoriel
Annexe – Description des variables du jeu de données ILPD
Nom du descripteur
Description
Age
Âge du patient en années. Peut influencer la prévalence et la gravité des maladies du foie.
Gender
Sexe du patient (Male ou Female). Certaines pathologies hépatiques sont influencées par le sexe.
Total_Bilirubin
Taux total de bilirubine dans le sang. Indique un dysfonctionnement hépatique ou une obstruction biliaire.
Direct_Bilirubin
Bilirubine conjuguée. Élevée en cas d’obstruction biliaire ou d’atteinte hépatique.
Alkaline_Phosphotase
Phosphatase alcaline. Élevée en cas de cholestase ou obstruction des voies biliaires.
Alamine_Aminotransferase (ALT)
Enzyme hépatique intracellulaire. Élevée en cas de cytolyse hépatique.
Aspartate_Aminotransferase (AST)
Enzyme intracellulaire moins spécifique. Élevée lors de lésions hépatiques.
Total_Proteins
Protéines plasmatiques totales. Révèle la capacité de synthèse du foie.
Albumin
Protéine synthétisée par le foie. Diminue en cas d’insuffisance hépatique.
Albumin_and_Globulin_Ratio
Rapport albumine/globulines. S’inverse en cas de maladies chroniques du foie.
Dataset
Variable cible : 1 = malade, 2 = sain.
Annexe – Glossaire des termes médicaux
- Bilirubine : Pigment jaune issu de la dégradation de l’hémoglobine, dont l'accumulation provoque l'ictère.
- Albumine : Protéine synthétisée par le foie, responsable du maintien de la pression osmotique.
- ALT (Alanine Aminotransferase) : Enzyme hépatique intracellulaire. Son élévation traduit une souffrance hépatique.
- AST (Aspartate Aminotransferase) : Enzyme intracellulaire retrouvée dans plusieurs organes, notamment le foie et le cœur.
- Phosphatase alcaline : Enzyme dont l’élévation indique une obstruction des voies biliaires ou une cholestase.
- Cytolyse : Destruction des cellules, en particulier des hépatocytes dans le contexte hépatique.
- Cholestase : Ralentissement ou arrêt de l’écoulement de la bile.
- Hypoalbuminémie : Diminution du taux d’albumine dans le sang, fréquente en cas de cirrhose.
-
 Orange Data Mining : https://orangedatamining.com/download/
Orange Data Mining : https://orangedatamining.com/download/